はじめに
こんにちは、システムエンジニアの kota です。
今回は、個人的にまだ触ったことのなかった GraphQL に入門してみたので、ブログとしてまとめてみました。
こんにちは、システムエンジニアの kota です。
今回は、個人的にまだ触ったことのなかった GraphQL に入門してみたので、ブログとしてまとめてみました。
ブラウザの開発者ツールはウェブ開発において必要不可欠なツールです。
開発者ツールを上手に使うことで、ウェブサイトのデバッグやパフォーマンスの最適化、アクセシビリティの向上など多くのことが行えます。
本記事では、ブラウザの開発者ツールの基本的な使い方や様々なテクニックについて解説します。

こんにちは。システムエンジニアの佐藤です。 続きを読む
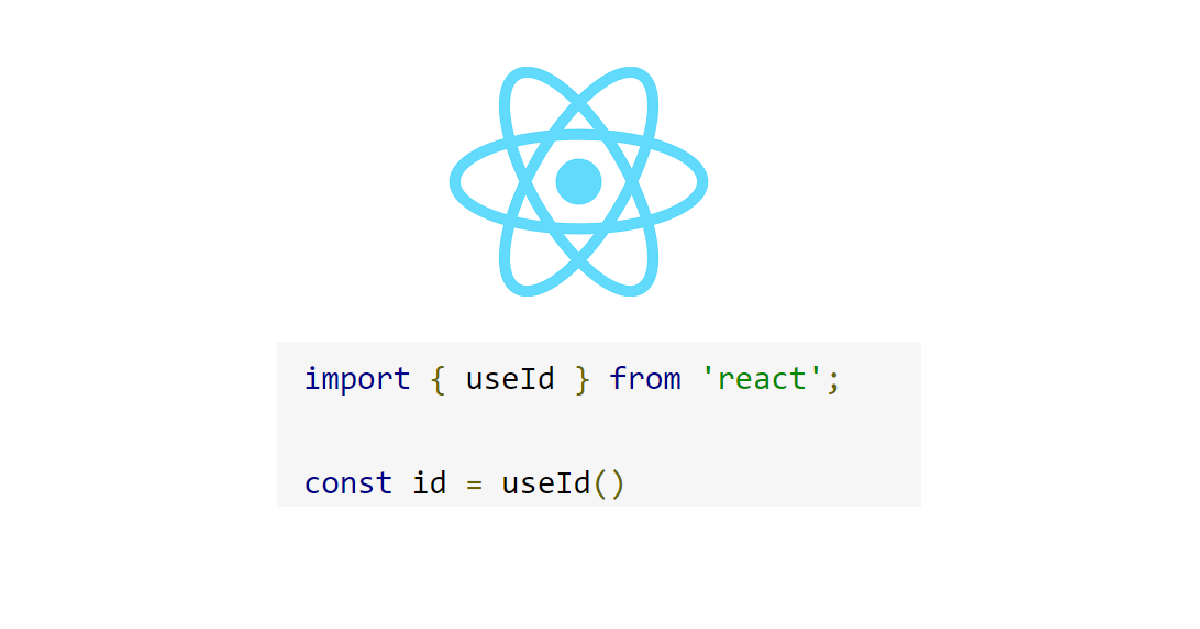
こんにちは WESEEK で yaml から css まで何でも書く haruhikonyan です。
フォームなどをコンポーネント化したときに同じページにそのコンポーネントを使うと id の重複に困ったりしませんか?
そんな時に React が公式で提供している useId という hook を使うと解決するかもしれません。
しかし利用においては注意点があるので具体例とともに紹介したいと思います。

はじめまして。エンジニアの Ryo です。本記事では、オンライン決済サービス Stripe を用いて海外展開をご検討中のサービス提供者向けに、気をつけておくべき点を紹介します。
※こちらの記事は、すでに Stripe をサービスに導入しているという前提で作成されております。もし、Stripe を検討中でまだ導入されてない場合は、以下の記事で Stripe 導入のメリットや扱うデータの種類、実際にサービスでどのように利用されているかなどを紹介していますのでご参照ください。

こんにちは。GROWI エンジニアの 宮沢 です。今回は便利な React hooks である SWR 2.0 で追加された useSWRMutation の使い所について簡単に紹介しようと思います。ある程度 SWR を使ったことがある人向けの記事となっております。 続きを読む

システムエンジニアの蛸井です。今回は Lerna についてと Lerna v6 の Nx の機能について解説します。
こんにちは、システムエンジニアの Kota です。今回は少し前に発表された SWR ver 2.0 に便利で新しいオプションが追加されたので、簡単に解説したいと思います。

こんにちは、 ryosuke です。
今回は、 vscode で devcontainer を使った開発環境について、 「Clone repository in container volume」を使うとうれしい点を取り上げます。

こんにちは、システムエンジニアの kouki です。
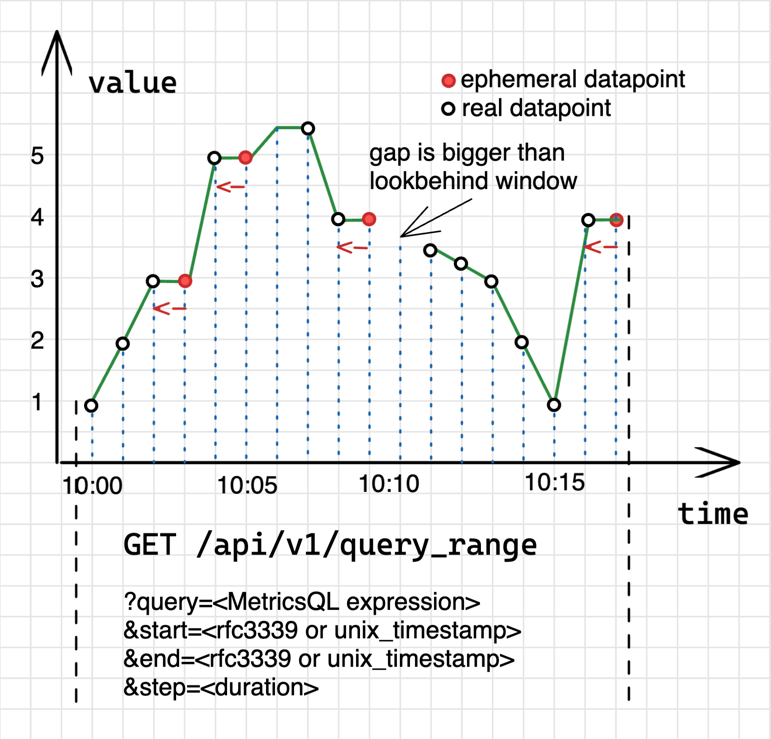
この記事では VictoriaMetrics のドキュメントに掲載されている Key concepts - VictoriaMetrics をハンズオン形式にまとめてみました。記事を書くに至ったモチベーションは下記の通りです。
ちなみに Key concepts では下記のような画像と共に VictoriaMetrics の挙動が解説されているので、非常に理解の助けになるドキュメントだと思います。