
この記事は、2021/5/27 に行われた WESEEK Tech Conference の内容です。
弊社が開発するSaaS型社内wiki・ナレッジベースサービス GROWI.cloud で、過去に発生した障害をピックアップしてご紹介します。
思い出すのもツラいところがありますが、発生した障害の中でも比較的大きいものを紹介しておりますので、
当時感じたツラさを感じてください。(^^;
記事内容と見どころ
障害に関連するシステム情報をはじめ、原因と対策は技術・運営の観点を紹介してますので、次の点が役に立つかもしれません。
- システム可用性の向上に対するヒント
- 同じプロダクトへの対策
- 似た構成への対策の参考
- 障害時の運営方針決定の参考
目次
1章. 大障害は準備が整ったと思った時にやってくる (障害Lv 1)
時は GROWI.cloud がオープンβ であった 2019/8/21~2020/9/3 の間、この SaaS を運用する前の準備を進めていた時のことです。
これから運用をする SaaS はどのようなサービスであり、どのようなシステム構成であり、監視はどうなっているのか?、運用ツールは何を使っていてどう見ればよいのか?、アラートが発生したらどうすればいいのか?、運用の目標は何か?を理解することを始めました。
どのようなサービスなのか?
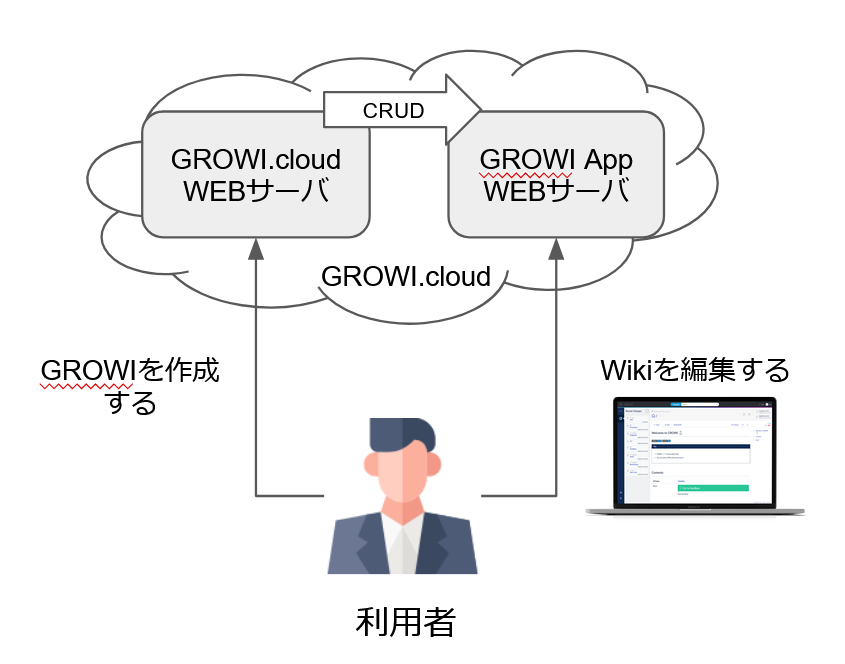
GROWI.cloud は OSS である GROWI をディプロイするサービスです。
利用者が GROWI をディプロイ(作成)したい場合は GROWI.cloud の WEB サーバへアクセスします。
そこで GROWI が作成されると、GROWI.cloud とは別に GROWI 用の WEB サーバが起動します。
(以降、この GROWI 用の WEB サーバを GROWI app と呼びます)
GROWI app の作成が終わると、利用者は GROWI app へアクセスして Wiki を編集することになります。
どのような構成なのか?
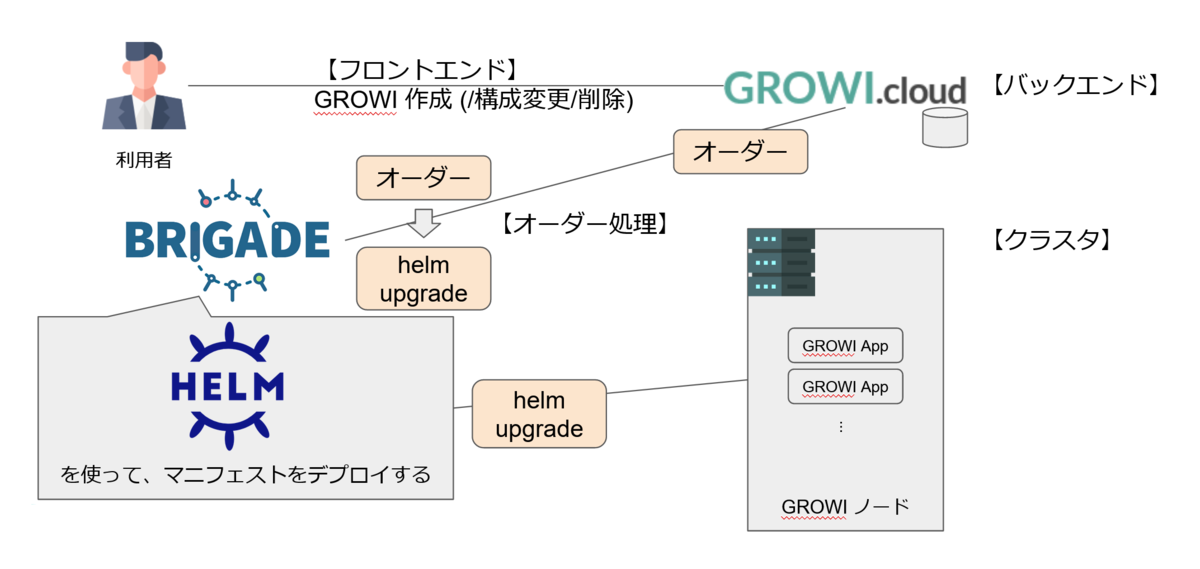
GROWI.cloud システムは役割によって、「フロントエンド」「バックエンド」「オーダー処理」「クラスタ」の 4 つに分類できます。
利用者が GROWI 作成(/構成変更/削除) 等の操作をするのは GROWI.cloud のフロントエンド、その操作を受け取るのがバックエンドです。
バックエンドでは利用者の操作はオーダーとして扱われ、brigade 1 がオーダーに対応する helm upgrade コマンドを生成・実行した結果、クラスタに GROWI app が作成されます。
(GROWI.cloud は kubernetes を使っており、helm upgrade は kubernetes クラスタのマニフェストセットを更新するコマンドです)
どのように監視をしているのか?
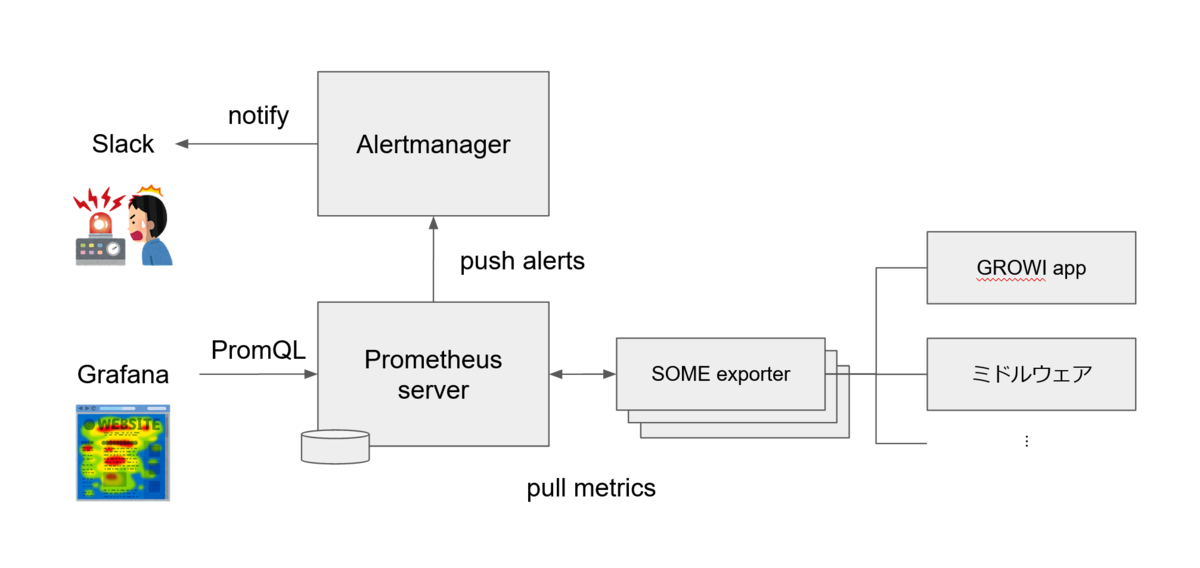
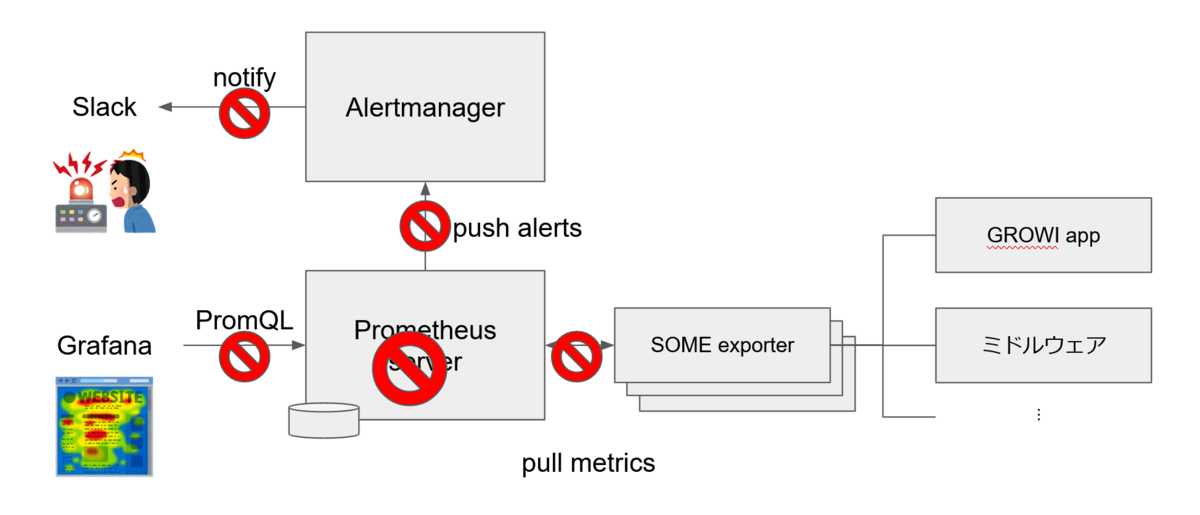
監視には Prometheus を使っています。
Prometheus は 3 つの component に分かれており、Prometheus server が監視対象の GROWI app やミドルウェアから exporter を介して定期的にデータを収集・保存し、Alertmanager へ送信したアラートが Slack へ通知されます。
また、Grafana が Prometheus server のデータをグラフ表示しています。2
ステータス確認方法は?
Grafana を使って Prometheus server のデータを表示することでステータスを確認しています。
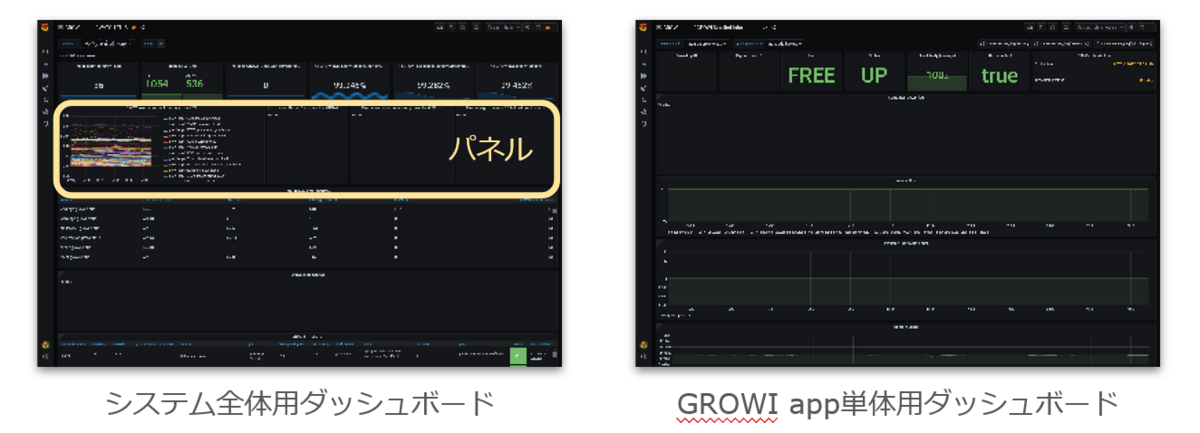
Grafana は画面を Dashboard として設定でき、Dashboard の中に表示する情報毎にパネルを配置できます。
GROWI.cloud の監視システムではシステム全体のステータスを確認する Dashboard や、GROWI app 単体のステータスを確認する Dashboard があり、次のようなステータスが表示されます。
-
システム全体用 Dashboard
- 稼働率
- 異常状態の GROWI app
- 他...
-
GROWI app 単体用 Dashboard
- プラン
- リソース使用率
- 他...
アラート発生時はどうするのか?
Wiki に対応手順が用意されており、アラートが発生した場合は対応する手順を実施することになります。
例えば GROWI app の URL へ HTTP アクセスが出来なくなった場合にアラートが発生するので、対応する手順を実施するといった具合です。
運用の目標は?
GROWI app の稼働率 99.9%3 を SLO として掲げています。
まだまだ至らないところですが、一日換算にすると許容できる停止時間は 86.44 秒なので、仮に停止した場合は迅速な対応が求められることが分かります。
また、障害が発生したときの緊急度としては次のように定義しています。(上から順に緊急度が高い)
- GROWI app が停止した
- Keycloak が停止した(GROWI app へのログイン不可)
- HackMD が停止した(GROWI app での同時多人数編集不可)
- Elasticsearch が停止した(GROWI app での全文検索不可)
- GROWI.cloud サイト障害
- バックアップできない
- 機能は提供できるが縮退状態
運用準備が整ったと思ったら発生した大障害
これまで紹介してきた内容を理解できたことで運用準備は万端だと思っていました。
アラートが発生しても対応する方法は明確ですし、異常が発生した原因は Grafana でステータス確認できるはずです。
どのくらいの緊急で対応すればよいのかも、緊急度や SLO に照らして考えれば自明です。
大障害が発生したのは、そのように考えていた矢先のことでした、、、
監視システムが全停止する事態となってしまっていたのです。
不幸中の幸いとして GROWI.cloud 利用者には何も影響がありません。障害緊急度の表に当てはめても一番低い事象です。
しかし、監視システムが全停止しているということは、システムの稼働状況の把握や、サービスの稼働率の計測、アラート通知が一切できません。
GROWI.cloud が稼働しているかは分からず、利用者が GROWI app を正常に使えるかも分からない盲目状態です。
SLO が達成できているかどうかも分からないため、サービス運営存続に支障が出てしまいます。
まずは状況確認
まずは状況確認をしたところ、Prometheus server が停止していることが分かりました。
監視の仕組みとして、Prometheus server が停止をすると定期的に監視対象からデータを収集・保存することも、Grafana でステータスを表示することも、アラートを通知することもできません。
次に Pod のステータスを確認すると Prometheus server が CrashLoopBackOff となっていました。4
kubernetes では Pod が停止した場合は kubelet が自動で起動します5が、短時間の間に Pod の再起動が繰り返されていると CrashLoopBackOff となるので、何か正常に起動が出来ていない原因がありそうです。
そこで Prometheus 起動時のログを確認すると、起動時の head chunk チェックで不整合が検出されたため、プロセスが起動できていないことが分かりました。
このメッセージを元に Prometheus の issue #7412 を確認すると、対処方法としては不整合が発生した head chunk ファイルを削除すればよいと判明し、なんとか光が見えてきました。。。
暫定復旧方法
しかし、どうやって不要な head chunk を消すかが悩ましいところでした。
再起動を繰り返す Pod は数秒しか起動できていないため、kubectl exec では shell を起動することが出来ません。(出来ても瞬時に停止してしまいます)
そこで考えた案は 3 つですが、いずれもうまくいきませんでした。
-
マニフェストの command を
sleep infinity等へ書き換える?- Podのcommandは書き換え不可6
-
マニフェストの restart policy を Never へ書き換える?
- StatefulSetのrestart policyはAlways以外設定不可7
-
同じ Persistent Volume (PV) を mount する Pod を立ち上げる?
- PV が ReadWriteOnce (RWO) であったため、別 Node で立ち上がった Pod からはアクセス不可8
しばらく良案がなく考えあぐねていましたが、 Prometheus が稼働していたノードへ ssh ログインする方法を知りました。
Pod が PV をマウントしているということは Pod が稼働しているノードがボリュームをマウントしているということです。9
つまりノードへ ssh すれば PV 内のファイルを削除できるはずです。
実際に Prometheus が稼働しているノードへ ssh ログイン10すると、無事に不整合が発生していたファイルを削除することが出来ました。
$ kubectl get pvc
storage-volume-admin-prometheus-server-0 Bound pvc-bf8d8e4c-7561-11e9-bef2-42010a920054 XXXGi RWO XXXXX XXXd
$ mount | grep bf8d
/dev/sdb on /var/lib/kubelet/plugins/kubernetes.io/gce-pd/mounts/gke-growi-cloud-prod-c-pvc-bf8d8e4c-7561-11e9-bef2-42010a920054 type ext4 (rw,relatime,data=ordered)
:
# cd /var/lib/kubelet/plugins/kubernetes.io/gce-pd/mounts/gke-growi-cloud-prod-c-pvc-bf8d8e4c-7561-11e9-bef2-42010a920054/chunks_head
# ls
000618 000619 000621 000622
# rm -f 000621 000622
# ls
000618 000619大障害1のまとめと恒久対策
大障害1 のまとめは次のとおりです。なんとか盲目の状態から光のある運用の世界が戻ってきました。
-
事象
- Prometheus server が停止した
-
原因
- Prometheus の head chunk に不整合が起こり起動しなくなった
-
影響
- システムの稼働状況の把握や、サービスの稼働率の計測、アラート通知が一切できず、サービス運営存続に支障が出てしまう
-
暫定復旧方法
- ノードへ ssh して不整合を起こした head chunk を削除した
この head chunk が不整合を起こす事象は Prometheus v2.19.1 以降では発生しないと issue に書かれていたため、恒久対策として Prometheus のバージョンアップを行いました。
また、Prometheus server が停止したことを即時検知できるよう、GROWI.cloud の監視システムを別の監視システムから監視する設定を追加することも併せて行いました。
監視システムはシステム運用・サービス運営のかなめです。
監視システムの停止は先が真っ暗になるような大障害でした。
2章. そのリソースが足りなくなるとは思わなかった (障害Lv 2)
システムリソース管理
話は GROWI.cloud というサービスの設計についてのことです。
GROWI.cloud ではサービス運営において必要なシステムリソースを、自動でスケールさせるか手動でスケールするかを求められる頻度や重要度に応じて使い分ける方針を取っています。
例えば、利用者がサービスを利用して「Wiki を作りたい」と思った場合に GROWI app を作成するリソースを用意することを考えた場合、サービスが人気になれば頻度は上がることが分かりますし、SaaS サービスとしてここを自動化できないと意味がないくらいに重要です。
いつ利用者が GROWI app を作成してもよいよう、必要なリソースは自動でスケールする必要があります。
一方で、監視システム等のシステム維持に必要なリソースをスケールさせることを考えると、頻度は比較的少ないと言えます。
運用負荷低減の観点では重要ですが、自動化の難易度も高いこともあり、手動でスケールさせる方針を取っています。
つまりはリソースを監視し、不足している場合はメンテナンス作業で対応することになります。
GROWI app の増加に伴い増えるリソース
GROWI app が増えることにより必要となるリソースの中で、最も影響度が大きいのは Kubernetes ワーカーノードの数です。
その他は影響がないか、影響度が低いと言えます。
| GROWI app数の増加 ------------------ | ----------------------------------------------
Kubernetes ワーカーノード | 必要数の増加
GROWI.cloud WEBサーバ | 影響なし
brigade | 影響なし
helm | インストールchart数の増加
Kubernetes マスターノード | 影響なし
要するに 1 台のノードで稼働できる GROWI app の数には限界があるので、GROWI app の数が増えたら Kubernetes ワーカーノードを増やす必要があるということです。
Kubernetes ノード数を自動で増やす仕組み
ノードやクラスタのオートスケーラーは Cluster Autoscaler と呼ばれ、GKE は Cluster Autoscaler を Google cloud console 画面から操作することが出来ます。
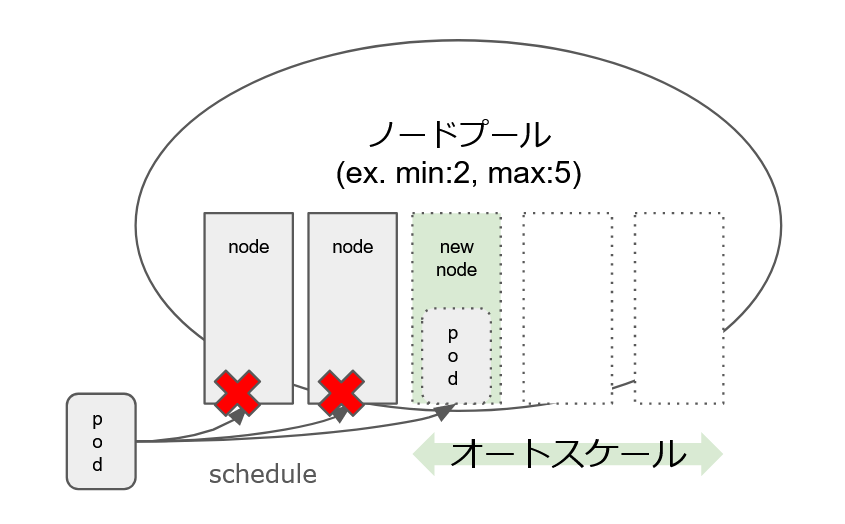
オートスケールはノードプール(ノードの集まりを指す概念)に対して指定し、min/max(per zone) が指定可能です。11
オートスケールを設定すると、Pod を schedule する際に Pod の request resource 分の空きがあるノードが枯渇した場合、新しいノードが追加されるようになります。
例えばノードプールに最小(min):2、最大(max):5のノードプールが設定された場合に Pod がすでにある 2 つのノードへ schedule できない場合は、新たに 1 つのノードが追加されるようになります。
ノードのオートスケールができるようになったが、あるリソースの枯渇によって発生した大障害
オートスケールが設定されたことで、GROWI app の数が増えて Kubernetes ワーカーノードが足りなくなった場合にも自動で Kubernetes ワーカーノードを追加できるようになりました。
Kubernetes ワーカーノード以外のリソースは GROWI app が増えても影響がなかったり、影響が少ないと言えるものであることは検討済ですし、
ノードプールは用途に応じて用意して GROWI app 用のノードプールは十分な数を設定しておいたのでオートスケールの最大値に到達することも心配ありません。
完璧な設定(もちろん誇張表現です ^^;)ができたので、GROWI app のためのリソースが足りなくなることはないだろうと思っていた時に発生した大障害がありました、、、
それは、いくつかの GROWI app が停止して長時間起動してこないという事象が起こり、同様の事態が色々な GROWI app で発生するというものです。
GROWI app の停止はノード単位で起こっており、特定のノードだけではなくいくつものノード起こってました。
つまりは、何人もの利用者が Wiki を一切使えない状態なので、利用者の怒る顔がありありと浮かぶ事態でした。
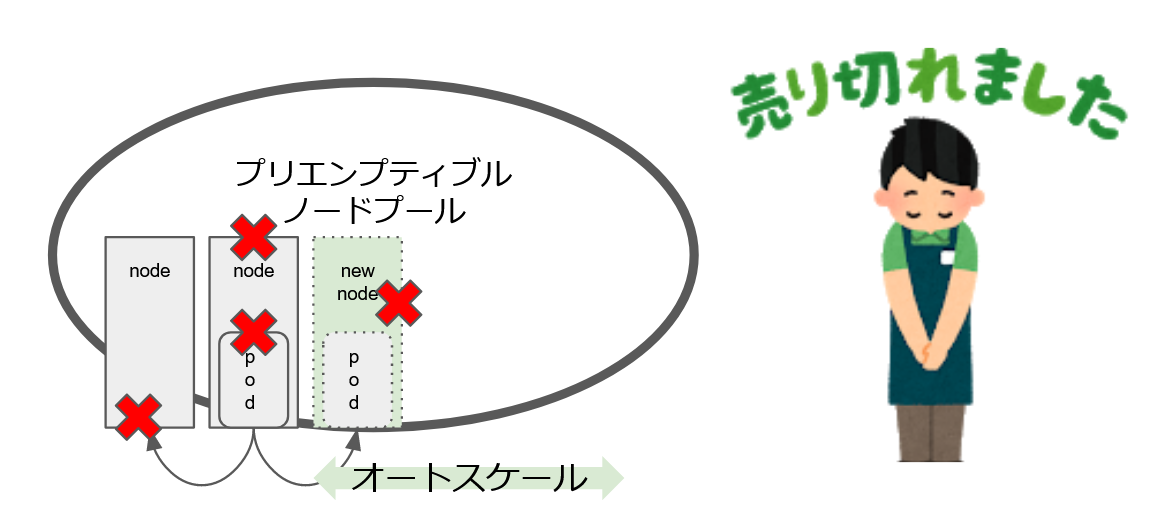
ここで、事象が起きているノードがプリエンプティブルノードという 24h 以内に必ず再起動が発生するという特徴を持つノードでした。
つまり、時間経過と共に影響が拡大することが予想され、SLO を維持できなくなることが明白です。
まずは状況確認
GROWI app の Pod が起動できていないのは、稼働するノードが足りていないためでした。
となると、「ノードプールのオートスケール最大値に達しているのではないか?」ということが疑われます。
しかし、オートスケール最大値に達しているということはなく、更には影響を受けた GROWI app は直近で作成されたものではなく、作成時刻は古いものでした。
つまり、稼働していた GROWI app が一度停止したあと、稼働するノードが見つからないという状況です。
稼働している GROWI app が停止するということはノードの停止なり削除が行われていることが疑われます。
オートスケールによるノード削減はあり得ますが、削除される条件はノードのリソースが有り余っている場合であり、GROWI app には適切な request resource が設定されているため、この線は考えにくいと言えます。
気がかりなのは事象が発生しているのがプリエンプティブルノードで稼働している GROWI app です。
その線で調査を進めると、プリエンプティブルノードの在庫が枯渇していることが分かりました。
ノードは GKE が提供するリソースであり、それを利用している GROWI.cloud としては GKE 側で在庫を増やしてもらわないとノードを追加することが出来ません。
また、プリエンプティブルノードが 24h 以内に再起動するという仕様の実態は、ノードプールからのノードと削除と追加というものでした。
ノードが削除されることで GROWI app が停止し、ノードを追加しようと動くがプリエンプティブルノードの在庫が枯渇しているため追加できず、GROWI app が起動できないといった状況だったのです。
検討・暫定対応したこと
プリエンプティブルノードの在庫枯渇が解消される目途は不明です。
ノードの在庫がなくなっているということは GKE 側でシステムリソースがなくなっていると予想されますので、システムへ新しいリソースを追加するのには時間がかかりそうです。
早くて数日、長くて数カ月かかるかもしれません。
もし数日/数か月かかるとしたら GROWI.cloud ユーザーには目も当てられません。
そこで、暫定対応としてノンプリエンプティブルノードを購入し、プリエンプティブルノードから GROWI app を移動させるという対応を行いました。
「そもそも本番サービスでプリエンプティブルノードを使うなよ」という感想を抱かれるかもしれませんが、下位プランの運用コストを如何に下げるかというチャレンジです。
チャレンジの詳細は「コスト7割減!Kubernetes本番サービス環境の運用ノウハウ」をご覧ください。
https://weseek.co.jp/tech/109/
大障害2のまとめと恒久対策
大障害2 のまとめは次のとおりです。利用者の怒る顔が和らいだことと信じています。
-
事象
- 長時間 GROWI app が停止し影響数も増加
-
原因
- プリエンプティブルノードの在庫が枯渇した
-
影響
- 多くの GROWI app にて、稼働するノードがなくなり長時間停止した
-
暫定復旧方法
- ノンプリエンプティブルノードを購入して GROWI app を稼働させた
プリエンプティブルノードの在庫事情は GKE のみ知る事情で、枯渇を防ぐことはできません。
そのため、再発時に退避を迅速に行えるよう nodeAffinity を設定して緊急時にノードを退避する設定したことを以って恒久対策としました。
クラウドサービスを使っていると忘れがちですが、システムリソースには必ず限界があるということを痛感した大障害でした。
3章. WEBアプリケーションの操作が失敗するのは内部が原因とは限らない (障害Lv 1)
GROWI.cloud という SaaS
GROWI.cloud システムは役割によって、「フロントエンド」「バックエンド」「オーダー処理」「クラスタ」の 4 つに分類できます。
-
フロントエンド
- ログイン画面、組織の作成・変更操作、GROWI app の作成・変更操作
-
バックエンド
- ログイン機能、組織/GROWI app データ保存、オーダー実行
-
オーダー処理(brigade, helm含む)
- オーダーを解釈し、対応する helm コマンドを生成・実行する
-
クラスタ(kubernetes cluster)
- GROWI app の稼働、GROWI.cloud システムプロセス稼働
フロントエンドは利用者が GROWI.cloud を操作する画面を指し、その操作を処理するのがバックエンドです。
バックエンドの処理の中でも GROWI app を作成するような操作はオーダーとして扱い、オーダーの処理は brigade にて行います。
オーダー処理はオーダーに対応する helm upgrade コマンドを作成・実行します。
(GROWI.cloud は kubernetes を使っており、helm upgrade は kubernetes クラスタのマニフェストセットを更新するコマンドです)
クラスタでは helm upgrade コマンドでインストールされた GROWI app が稼働します。(GROWI.cloud のシステムプロセスもクラスタで稼働します)
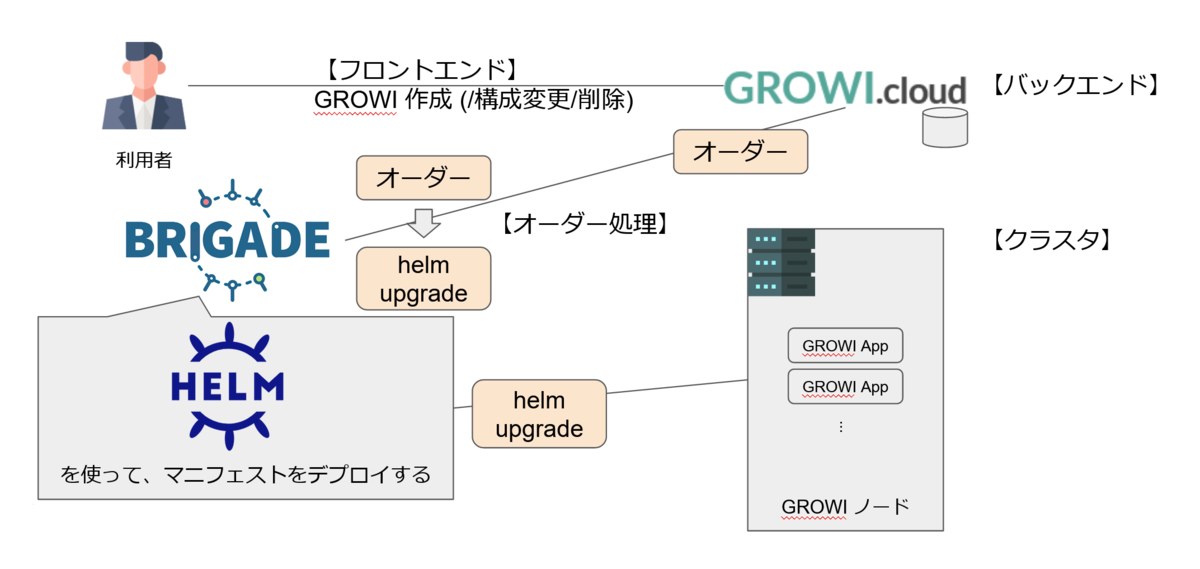
このように、GROWI.cloud は GROWI appの作成・変更操作等をオーダーとして扱い、オーダーを処理する結果としてクラスタ内の GROWI app を CRUD するシステムと言えます。
オーダー処理により利用者の操作を自動でクラスタへ反映できる構成で、内部が原因ではなく失敗を起こした大障害
オーダー処理により利用者が行う次のような操作は自動でクラスタへ反映できます。
- GROWI app を新しく作成する
- 不要となった GROWI app を削除する
- GROWI app のバージョンを変更する
- 独自ドメインを設定する
- 証明書を設定する
GROWI.cloud は画面上の操作をきっかけとしていくつかのシステム内部の機能が連動することで、クラスタの操作が自動化出来ています。
いくつかの機能が内部で連携しているため、この中のどれかがバグや停止などで連携できなくなった場合はオーダー処理が出来なくなります。
しかし、内部以外の要因でもオーダー処理がうまくいかなくなる潜在的な要因があり、それがあらわになる大障害が起こりました、、、
起こった事象としては、利用者が GROWI app の新規作成や変更操作が失敗し、それが連続するといったものでした。
既に作成した GROWI app であれば使える(つまり GROWI の Wiki ページを閲覧・編集などはできる)ものの、
GROWI.cloud の新規利用者を獲得する機会を失うことに繋がり、既存ユーザーはバージョンアップデートなどが出来ず不便な思いをさせてしまいます。
当時 GROWI.cloud を操作した利用者には、よく分からず処理が成功しない苛立ちを覚えさせてしまったことでしょう。
まずは状況確認
GROWI.cloud の画面から操作を行った結果からオーダーを作成し、それが brigade によってイベント検知して処理が開始されているところまでは正常に行われていることが分かりました。
フロントエンド・バックエンド・クラスタは白で、問題はオーダー処理にありそうです。
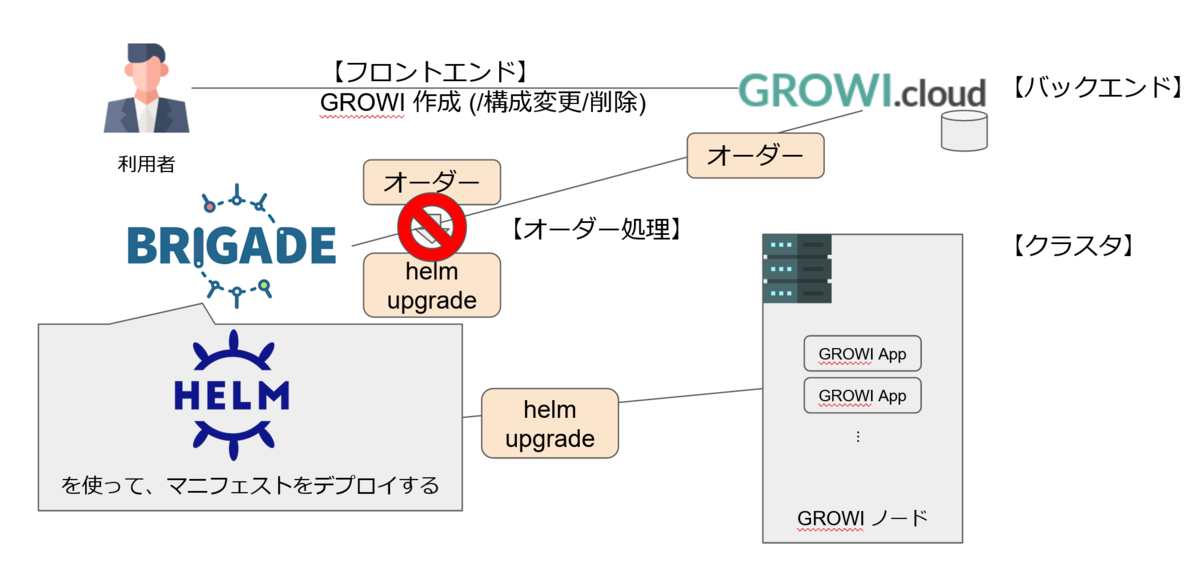
brigade では Gateway が何かの条件を Trigger として Event を発行し、Job を Build するという処理が行われます。
オーダー処理としては、オーダーに対応する Event を発行して、helm update を実行する Job を Build するということを指します。
この流れを追っていくと、Job を Build する処理が失敗していることが分かりました。
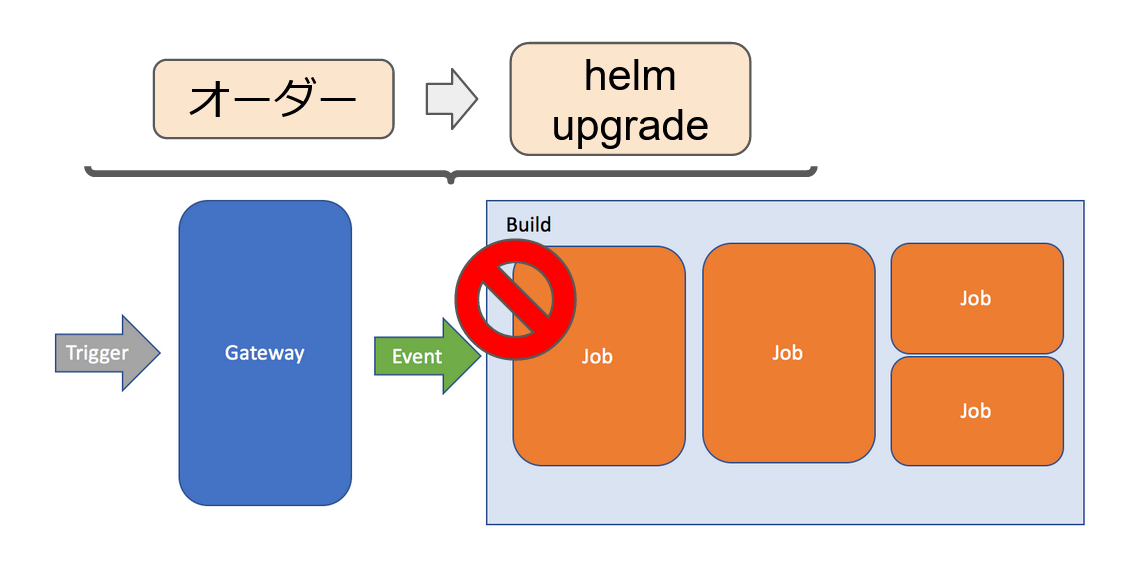
Job の Build では Node.js のアプリケーションを実行する処理が行われます。
そこではアプリケーションに依存する npm パッケージを都度 npmjs サイトからダウンロードする必要があり、npm パッケージがダウンロードできないことから npmjs サイトの障害 12 が判明しました。
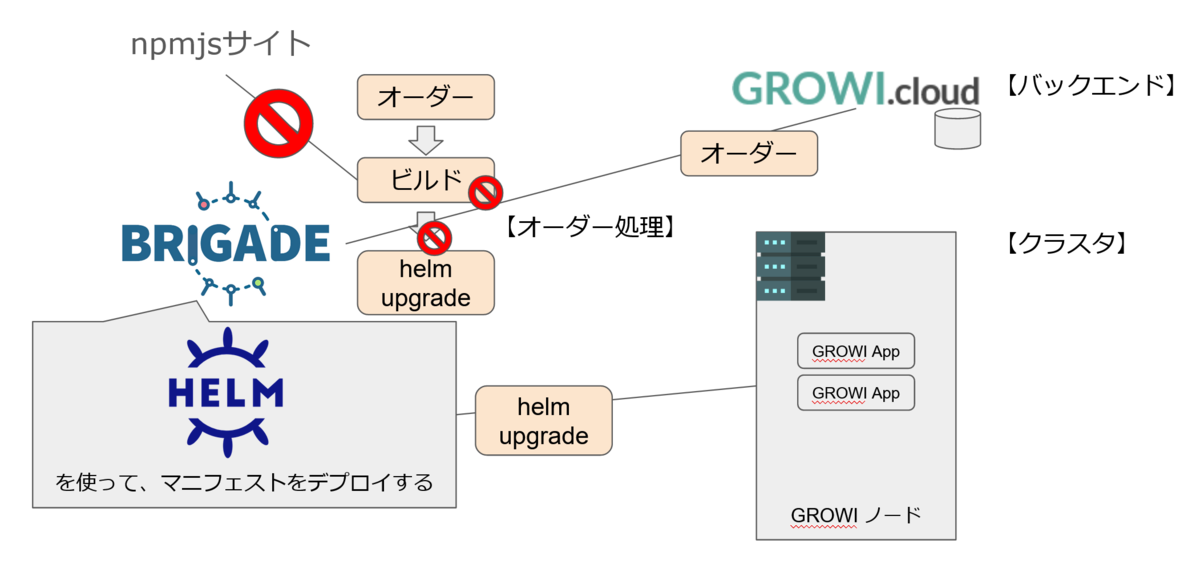
npmjs サイトの障害という外部要因によりパッケージのダウンロードができず、事象としては GROWI.cloud でオーダー処理が出来なくなるという結果を引き起こしていました。
検討・暫定対応したこと
npmjs サイトの障害復旧目途は不明でしたが、障害情報に書かれた対応状況の変化は早く、長くても 1 週間はかからないであろうという印象を受けました。
ただし、復旧の目途はあれど npm のパッケージがダウンロードできないことには対応する手段がなく、早い復旧を祈るしかありませんでした。
そのため、暫定対応はとることが出来ず GROWI.cloud の News と Twitter 通知にて障害通知のアナウンスをし、その後 npmjs サイトが復旧したことを確認して復旧通知をアナウンスしました。
復旧対応を実施することが出来ないというのはもどかしいものです。
大障害3のまとめと恒久対策
大障害3 のまとめは次のとおりです。利用者が不便を感じて GROWI.cloud の利用開始を諦めなかったことを祈るばかりです。
-
事象
- GROWI app の新規作成及び更新操作の失敗が多発
-
原因
- npmjs サイトの障害により一切の npm のパッケージダウンロードができなくなった
-
影響
- GROWI app の新規作成及び更新ができない
-
暫定復旧方法
- なし (障害アナウンスのみ)
npmjs サイトの障害でパッケージがダウンロードできないことが原因だったので、恒久対応として npm パッケージを SCM repository に含め、都度ダウンロードしなくて済むようにしました。
また、npm パッケージを SCM repository に含めるにあたり、依存するnpmパッケージ数を減らしもしました。
アプリケーションを開発する時も npmjs サイトから npm パッケージをダウンロードする機会は多く、使えなくなるということを気にすることがありませんでしたが、起こってみるとなかなかインパクトが大きいと感じる大障害でした。
障害を振り返って思うこと
備えていても障害は起こるものなので、基本的ですが、一度起こってしまったことが再発しないよう恒久対策を行い、再発の可能性があれば緊急回避手段を用意することが重要だと思います。
また、障害発生時と暫定復旧方法を考える際には、稼働率の維持だけを絶対の指標とするのではなく、ユーザーの満足度も忘れないようにするのが重要だと感じました。
予告
機会があれば、今回紹介した大障害とはまた別の障害を「大噴火編」として紹介しようと思います。
著者プロフィール
佐藤 龍
株式会社WESEEK / システムエンジニア
サポートセンターにてインシデント対応のテクニカルエンジニアを経験後、2017年12月にWESEEKに入社。
現在は、大手IXの業務自動化システムの機能開発やGROWI.cloudのインフラ構築・運用に携わる。
学習したことは Qiita などでアウトプットしている。(https://qiita.com/tatsurou313)
お酒が好きだが飲みすぎてしまうのが悩みの種。
株式会社WESEEKについて
株式会社WESEEKは、システム開発のプロフェッショナル集団です。
【現在の主な事業】
- 通信大手企業の業務フロー自動化プロジェクト
- ソーシャルゲームの受託開発
- 自社発オープンソースプロダクト「GROWI」「GROWI.cloud」の開発
GROWI
GROWIは、Markdown記法でページを記述できるオープンソースのWikiシステムです。
【主な特徴】
- テキストも図表もどんどん書ける、強力な編集機能
- チーム拡大に迅速に対応できる管理者向け機能を提供
- 充実した機能・サポートでエンタープライズにも対応
GROWI.cloud
GROWI.cloudはOSSのGROWIを専門的知識がなくても簡単に運用・管理できる、法人・個人向けの商用サービスです。
大手Sier・ISPから中小企業・大学などの教育機関まで幅広くご利用いただき、さらに個人や大学サークルでもご利用いただいています。
【導入事例記事】
インターネットマルチフィード株式会社様
https://growi.cloud/interviews/mfeed/?utm_source=connpass-top&utm_medium=web-site&utm_campaign=mf
株式会社HIKKY(VR法人HIKKY)様
https://growi.cloud/interviews/hikky
WESEEK Tech Conference
WESEEK Tech Conferenceは、株式会社WESEEKが主催するエンジニア向けの勉強会です。
月に2回ほど、WESEEKに所属するエンジニアが様々なテーマで発表を行う予定です。
次回は、6/10(木) 19:00~20:00に開催予定です。
『普遍的そして実践的! ノンデザイナーのためのデザイン原論』と題して、COSMORENA, Inc. 代表の形部さんがお話します。
現在、connpassやTECH PLAYで参加受付中です。皆様のご参加をお待ちしております!
https://weseek.connpass.com/event/214095/
TECH PLAYはこちらから
一緒に働く仲間を募集しています
東京の高田馬場オフィス、大分にある別府サテライトオフィスにてエンジニアを募集しております。
中途採用だけではなく、インターンシップも積極的に受け入れています!
詳しい募集要項は、弊社HPの採用ページからご確認ください。
- Brigade | Event-driven scripting for Kubernetes.
- Prometheus Overview
- 99.9% は、旧スタンダードプラン以上、'21/5/13リリースの新法人プランではベーシックプラン以上での提供です
- トラブルシューティング | Kubernetes Engine ドキュメント
- Liveness Probe、Readiness ProbeおよびStartup Probeを使用する
- Kubernetes API Reference Docs
- restartPolicy: Unsupported value: "Never": supported values: "Always"
- 永続ボリューム
- 詳解KubernetesにおけるPersistentVolume
- Using SSH to connect to a cluster node | Anthos clusters on VMware
- クラスタ オートスケーラー | Kubernetes Engine ドキュメント | Google Cloud
- https://status.npmjs.org/incidents/cksjqc1w11v5

