
この記事は、2021/6/24 に行われた WESEEK Tech Conference の内容です。
弊社が開発するSaaS型社内wiki・ナレッジベースサービス GROWI.cloud で、過去に発生した障害をピックアップしてご紹介します。
思い出すのもツラいところがありますが、発生した障害の中でも比較的大きいものを紹介しておりますので、
当時感じたツラさを感じてください。(^^;
前回よりも障害の規模は大きめです。
記事内容と見どころ
障害に関連するシステム情報をはじめ、原因と対策は技術・運営の観点を紹介してますので、次の点が役に立つかもしれません。
- システム可用性の向上に対するヒント
- 同じプロダクトへの対策
- 似た構成への対策の参考
- 障害時の運営方針決定の参考
目次
GROWI.cloudというSaaS
障害について紹介する前に、まずは GROWI.cloud というサービスの構成・運用について紹介します。
GROWI.cloudとはどんなサービス?
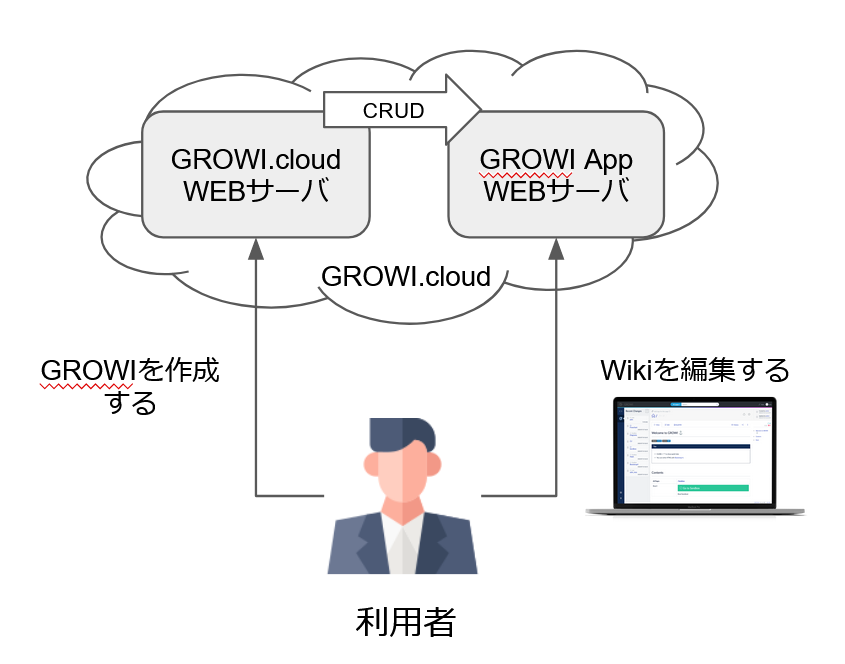
GROWI.cloud は OSS である GROWI をディプロイするサービスです。
利用者が GROWI をディプロイ(作成)したい場合は GROWI.cloud の WEB サーバへアクセスします。
そこで GROWI が作成されると、GROWI.cloud とは別に GROWI 用の WEB サーバが起動します。
(以降、この GROWI 用の WEB サーバを GROWI app と呼びます)
GROWI app の作成が終わると、利用者は GROWI app へアクセスして Wiki を編集することになります。
GROWI.cloudはどんな構成?
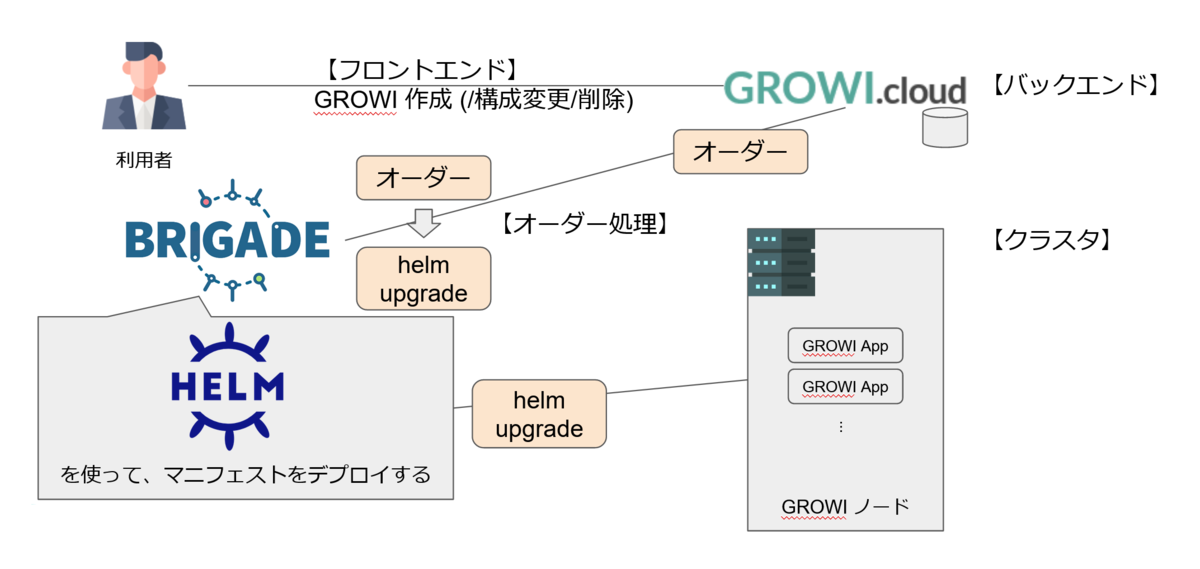
GROWI.cloud システムは役割によって、「フロントエンド」「バックエンド」「オーダー処理」「クラスタ」の 4 つに分類できます。
利用者が GROWI 作成(/構成変更/削除) 等の操作をするのは GROWI.cloud のフロントエンド、その操作を受け取るのがバックエンドです。
バックエンドでは利用者の操作はオーダーとして扱われ、brigade1 がオーダーに対応する helm upgrade コマンドを生成・実行した結果、クラスタに GROWI app が作成されます。
(GROWI.cloud は kubernetes を使っており、helm upgrade は kubernetes クラスタのマニフェストセットを更新するコマンドです)
運用の目標は?
GROWI app の稼働率 99.9%2 を SLO として掲げています。
まだまだ至らないところですが、一日換算にすると許容できる停止時間は 86.44 秒なので、仮に停止した場合は迅速な対応が求められることが分かります。
また、障害が発生したときの緊急度としては次のように定義しています。(上から順に緊急度が高い)
- GROWI app が停止した
- Keycloak が停止した(GROWI app へのログイン不可)
- HackMD が停止した(GROWI app での同時多人数編集不可)
- Elasticsearch が停止した(GROWI app での全文検索不可)
- GROWI.cloud サイト障害
- バックアップできない
- 機能は提供できるが縮退状態
1章. 生かすべきか殺すべきか、それが問題だ (障害Lv 3)
「生かすべきか殺すべきか」を考えさせられることになった大障害について紹介します。
クラスタは正常な状態のアプリを維持してくれる
GROWI.cloud で使用している kubernetes クラスタはアプリを定期的に診断し、異常な場合は再起動します。3
この診断は livenessProbe により行われます。livenessProbe にはアプリが正常である場合に Success となる処理を定義します。
すると kubernetes クラスタは livenessProbe が Failure になるとコンテナを KILL するようになります。
KILL されたコンテナは restartPolicy に従い起動します。その結果、アプリは常に正常な状態を維持できます。
つまり、アプリが正常状態であるか、異常状態であるかを定義することが重要です。
GROWI app が提供している機能
アプリが起動しているだけで正常であるとは言えません。一部の機能が使えなくなっている可能性があります。
では、クラスタが診断するアプリである GROWI app が正常・異常状態であることを考えるにあたり、そもそも GROWI app にはどのような機能があるかを考えてみます。
GROWI が提供する機能には Wiki、全文検索、同時多人数編集機能、ユーザー認証機能、メール送付、Slack 通知、等があります。
この中のどの機能が使える状態が正常状態であり、どの機能が使えなくなる状態を異常状態とするのがよいでしょう?
機能によってはミドルウェアと接続が必要なものがあります。
ミドルウェアに接続するときに使うドライバが常時接続(初期化タイミングが1回だけも含む)しているか、機能を使うタイミングで都度接続をするかといった違いがあります。
都度接続するドライバについては、何かエラーが起こってもユーザーがリトライすれば再び機能を使うことが出来るようになります。
しかし、常時接続するドライバについては、何かエラーが起こった時に再接続できない場合はその機能が使えなくなってしまいます。
つまり、ミドルウェアと常時接続していてミドルウェアに再接続できない機能が使えなくなった場合はアプリが異常であると定義し、それ以外の場合を正常であると定義するとよさそうです。
表中では『Wiki』『全文検索』『同時多人数編集』の 3 つが当てはまります。
| GROWI の機能 | ドライバ | 常時接続 | 再接続可否 |
|---|---|---|---|
| Wiki | MongoDBとの接続 (mongoose) | YES | NO |
(実装依存) ※1
全文検索 | Elasticsearchとの接続 (elasticsearch.js) | YES | NO
(実装依存) ※2
同時多人数編集(HackMD) | MariaDBとの接続 (Sequelize) | YES | NO
(実装依存) ※3
ユーザー認証(各種認証ミドルウェア・認証機構を利用) | - | NO | -
メール送付、Slack通知、・・・ | 各種ツール | NO | -
GROWI app のヘルスチェックを行う
GROWI app が異常である状態とは、ミドルウェアと常時接続していて再接続できない機能である『Wiki』『全文検索』『同時多人数編集』が停止した場合であると定義しました。
これらの機能は 1 度でも使えなくなると回復できないため、いつの間にか使えなくなっても自然復旧はしません。
いつの間にか使えなくなった場合、ユーザーに不便を感じさせてしまう可能性があり、サービスとしては機能を回復させる手段を取る必要があります。
そこで、各機能についてヘルスチェックを行うことにします。
『Wiki』『全文検索』については GROWI のヘルスチェック API へミドルウェアとの接続性を確認するクエリ付きでアクセスすることでヘルスチェックできます。7
『同時多人数編集』については HackMD のヘルスチェック API へアクセスすることで DB との接続性を含めてヘルスチェックできます。8
これらのヘルスチェックを kubernetes の livenessProbe に設定することで、ミドルウェアと接続できなくなった場合は自動で GROWI app が再起動できるようになります。
GROWI app が常に正常な状態を維持するようになったにも関わらず起こった大障害
kubernetes の livenessProbe にヘルスチェックを設定することで、GROWI app は常に正常な状態を維持するようになりました。
この設定により、いつの間にか『Wiki』が使えなくなった場合、いつの間にか『全文検索』が使えなくなった場合、いつの間にか『同時編集機能』が使えなくなった場合、どの場合でも自動で復旧することが出来るようになりました。
完璧ですね。(もちろん誇張です ^^;)
しかし、このような常に正常な状態を維持できるように設定したにも関わらず起こってしまった大障害がありました、、、
それはGROWI app が頻繁に再起動するといった事象でした。
1 つの GROWI app において再起動が繰り返され、同様の状態が多数の GROWI app で起こっていました。
GROWI app が頻繁に再起動していてはユーザーは GROWI を一切使用することが出来ません。同じことが複数のユーザーで起こっていることを考えるとユーザーの激怒する顔が浮かびます・・・
当然、早々に SLO が維持できなくなってしまう状況 でした。
まずは状況確認
GROWI app の Pod の状況を確認すると livenessProbe が失敗しており、そのために Pod が再起動されていることが分かりました。
また、特定のノードで稼働する Pod だけではなく複数のノードでも同様であったため、Pod 側の問題である HTTP サーバが応答しないことは考えづらい状況でした。
となると、livenessProbe で確認しているミドルウェアで問題が起こっている可能性が疑われます。
そこで、ミドルウェアの状態を確認しましたが、DB のクラスタステータス・負荷は問題ありませんでしたが、Elasticsearch がクラスタステータスは問題ないものの負荷が高騰していることが分かりました。
つまり、GROWI app からミドルウェアへ接続は出来ていたものの負荷により応答時間が平常時よりも長く、livebessProbe の timeout 時間(defaultは1秒)を超えてしまっている状況ということが分かりました。
検討・暫定対応したこと
Elasticsearch の負荷が高騰した理由は不明であり、ヘルスチェックの間隔9を長くしても、Elasticsearch のリソースを増強を試みるも大きな改善は見込めず、復旧の目途は立ちませんでした。
そこで、GROWI app が再起動する状況と、全文検索機能が使えなくなっているかもしれない状況にするかのいずれかを選択することになり、SLO の観点からもユーザーとしても良いだろうということで、全文検索が使えなくなった場合に GROWI app は生かすべきという判断を行いました。
その判断を受けて、ヘルスチェックAPIのミドルウェア接続性を確認するクエリを外すという暫定対応を実施して事象を復旧させました。
大障害1のまとめと恒久対策
-
事象
- GROWI app再起動の多発
-
原因
- Elasticsearchの負荷高騰によりレスポンスが低下した
-
影響
- 多数のGROWI appに対してヘルスチェックが失敗し、再起動を繰り返した
-
暫定復旧方法
- 一時的にヘルスチェック時のミドルウェアとの接続性を確認しないようにした
暫定対策により事象を復旧した後に行った恒久対策は次の2点です。
- GROWI の改修を開発チームへ依頼し、Elasticsearch との接続が失敗した場合は再接続できるようにし、またヘルスチェック API ではミドルウェア毎に接続確認できるようにした 10 , 11
- 上記改修後、GROWI app のヘルスチェック API を新しい仕様に併せて設定した
まさに、GROWI app を生かすべきか殺すべきかを考えさせられる大障害でした。
2章. デュラハンと化したクラスタ (障害Lv 5)
kubernetes のマスターノードとワーカーノード
GROWI.cloud は kubernetes クラスタを使っています。
kubernetes にはノードの種類があり、マスターノードとワーカーノードがあります。
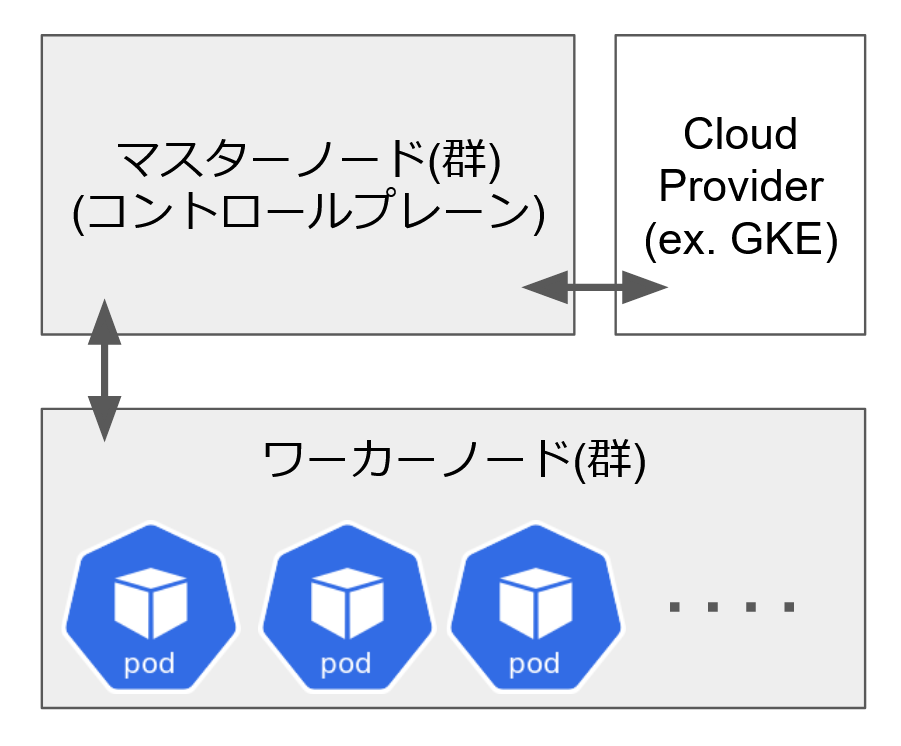
ワーカーノードはアプリケーションが稼働するノードを示し、稼働する単位は Pod と呼びます。
マスターノードはワーカーノードと Pod を管理し、クラウドプロバイダー固有の機能と連携します。クラウドプロバイダーは例えば GKE です。
マスターノードでは kube-apiserver コンポーネントが動作しています。
また、ワーカーノードでは kubelet が動作しています。
kube-apiserver はクラスタ内の全コンポーネントのステータスを把握し、コンポーネント間の連携する役割を持ちます。
kubelet はマスターノードからの指示に従い、ノード内で Pod を定義された状態を維持させる役割を持ちます。
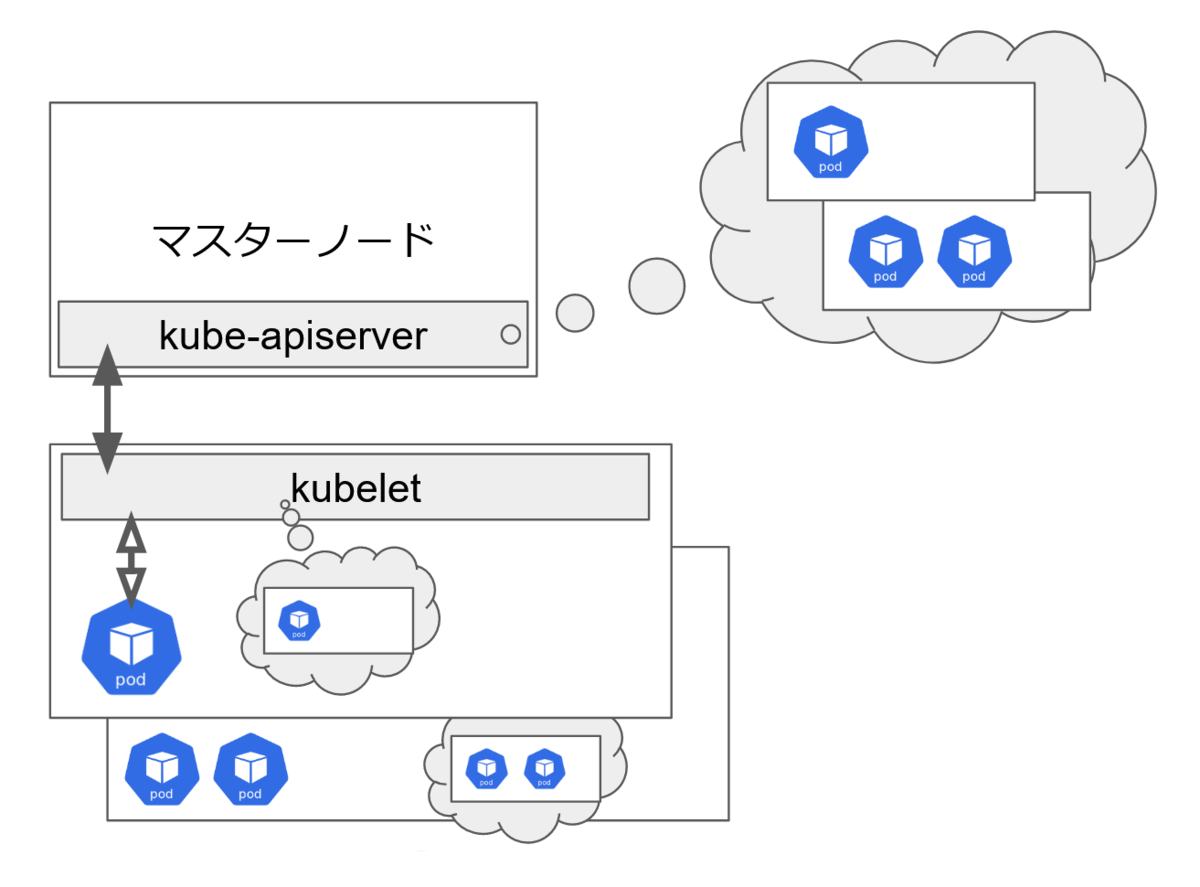
マスターノードの kube-apiserver がワーカーノードの停止を検知した場合、停止していたノードで稼動していた Pod を kube-scheduler が別ノードで稼動させるようスケジュールします。
それが kubelet に伝わると、新しいノードで Pod が稼働できるようになります。
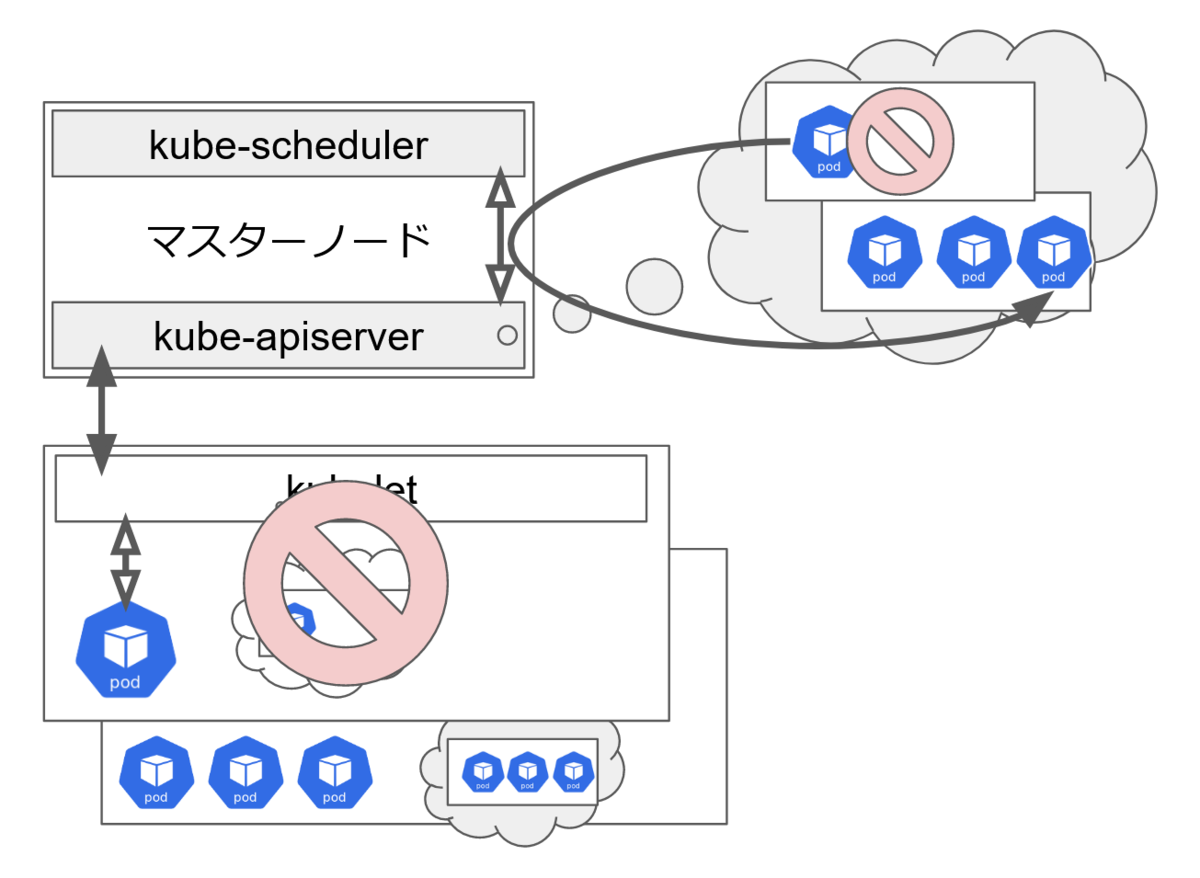
このように、kubernetes においてコントロールプレーンはいわゆる頭で、ワーカーノードは Pod が稼働する胴体のようなものです。
また、GROWI.cloud で利用している GKE ではマスターノードを管理してくれるため、GKE を利用する場合はワーカーノードと稼働する Pod を管理すればよいという利点があります。
このように、kubernetes クラスタは、ワーカーノードが停止してもアプリは別のワーカーノードで稼動させることが出来、コントロールプレーンが GKE が管理・運用してくれるので気にしなくてよい素晴らしいシステムです。
Pod が稼働するノードが落ちても自動で回復するので、ノードで何が起こっても問題は発生しないはずですね。(当然誇張です ^^;)
しかし、そのような kubernetes クラスタであっても起こってしまった障害がありました、、、
ノードが停止しても Pod が別ノードで稼働できる kubernetes クラスタにも関わらず発生してしまった大障害
GROWI app が停止して、時間が経つと同様の影響を受ける GROWI app が増加するという障害が発生しました。
GROWI app が停止することはユーザーが GROWI を一切使えないことを示します。
これはユーザーからすると憤慨ものです。。。
ユーザーの怒る顔が浮かび、障害緊急度の表に当てはめても一番高いことが焦りを生み、また刻々と影響を受ける GROWI app が増えていくという状況から SLO を維持することが出来なくのも時間の問題ということも緊張感を高めていました。
まずは状況確認
確認できたこととして、影響を受けた GROWI app はプリエンプティブルノードというノードで稼動している GROWI app であったということが分かりました。
そして GROWI app が停止するタイミングは、プリエンプティブルノードが再起動するタイミングでした。
しかし、プリエンプティブルノードの在庫が枯渇したということではなく、新しいプリエンプティブルノードは稼働しているにも関わらず Pod が新しいノードで稼動しないという状況でした。
では原因は何かとさらなる状況確認を進めようとしたものの、、、状況確認自体ができないということからマスターノードが停止していることが分かりました。
マスターノードは GKE により自動アップグレードが行われますが、そのアップグレード処理が失敗してリトライするということが繰り返されていました。(gcloud コマンド12で確認しました)
マスターノードのコンポーネントである kube-apiserver が停止すると kubernetes API が全て使えず、kubectl コマンドも全く応答できなくなり、要するに kubernetes クラスタの状態が取得できなくなります。
kube-apiserver と kube-scheduler が停止していたため、ワーカーノードが停止しても新しいノードで Pod を稼働させることが出来ない状況であることが分かりました。
まさに頭をなくして胴体だけで生きるクラスタが、我々に死を告げに来たような状況です。。。
そのような中、ある程度状況が理解できたのは、不幸中の幸いとして監視システムである Prometheus がワーカーノードで稼動出来ていたためでした。
Prometheus まで停止していたとするとクラスタの稼働状況は一切知ることはできなかったことでしょう。
検討・暫定対応したこと
マスターノードは GKE で管理していることを利点としてあげましたが、欠点として今回のように故障した場合は対応することが出来ません。
出来ることはクラウドプロバイダのサポートへ対応を依頼することのみなので、対応を依頼しました。
また、事象は1日の中で数時間に及び、マスターノードが稼働できる時間帯もあったもののアップデート処理が実行されないだけでアップデートは失敗しているため、翌日再実行され再度失敗するといったひどい状況でした。
我々が取れる暫定対応として、デュラハンとなったクラスタを胴体だけで少しでも長く生き続けられるような選択を取りました。
それは、ノンプリエンプティブルノードを購入し、マスターノードが稼働している隙間時間を狙ってプリエンプティブルノードから移動させる処理を行ったこと、Prometheus が停止しないようノンプリエンプティブルノードを占有する構成へ変更したことです。
大障害2のまとめと恒久対策
-
事象
- マスターノードが長時間・連日停止した
-
原因
- 不明(マネージドサービスのため)
-
影響
- その間に停止したプリエンプティブルノードで稼働していた多くのGROWI appが停止した
-
暫定復旧方法
- クラウドプロバイダのサポートに依頼した
- ノンプリエンプティブルノードを購入してGROWI app/Prometheusを延命させた
事象はサポートが対応することで数日後に復旧しました。
その後、マスターノードが冗長化されたリージョナルクラスタ13を構築して切り替えて恒久対策としました。
障害を振り返って思うこと
備えていても障害は起こるものなので、基本的ですが、一度起こってしまったことが再発しないよう恒久対策を行い、再発の可能性があれば緊急回避手段を用意することが重要だと思います。
また、障害発生時と暫定復旧方法を考える際には、稼働率の維持だけを絶対の指標とするのではなく、ユーザーの満足度も忘れないようにするのが重要だと感じました。
著者プロフィール
佐藤 龍
株式会社WESEEK / システムエンジニア
サポートセンターにてインシデント対応のテクニカルエンジニアを経験後、2017年12月にWESEEKに入社。
現在は、大手IXの業務自動化システムの機能開発やGROWI.cloudのインフラ構築・運用に携わる。
学習したことは Qiita などでアウトプットしている。(https://qiita.com/tatsurou313)
お酒が好きだが飲みすぎてしまうのが悩みの種。
関連記事
CircleCI 2.1とkubernetesで動作するアプリケーションの CI/CD 事始め
株式会社WESEEKについて
株式会社WESEEKは、システム開発のプロフェッショナル集団です。
【現在の主な事業】
- 通信大手企業の業務フロー自動化プロジェクト
- ソーシャルゲームの受託開発
- 自社発オープンソースプロダクト「GROWI」「GROWI.cloud」の開発
GROWI
GROWIは、Markdown記法でページを記述できるオープンソースのWikiシステムです。
社内WikiやオープンWikiとして活用されており、OSSであるためオンプレミス環境や各種クラウドVMに利用者自身で導入できるという自由度が人気を博しています。
GROWI.cloud
GROWI.cloudはOSSのGROWIを専門的知識がなくても簡単に運用・管理できる、法人・個人向けの商用サービスです。
大手Sier・ISPから中小企業・大学などの教育機関まで幅広くご利用いただき、さらに個人や大学サークルでもご利用いただいています。
【導入事例記事】
インターネットマルチフィード株式会社様
https://growi.cloud/interviews/mfeed/?utm_source=connpass-top&utm_medium=web-site&utm_campaign=mf
株式会社HIKKY(VR法人HIKKY)様
https://growi.cloud/interviews/hikky
WESEEK Tech Conference
WESEEK Tech Conferenceは、株式会社WESEEKが主催するエンジニア向けの勉強会です。
月に2回ほど、WESEEKに所属するエンジニアが様々なテーマで発表を行う予定です。
次回は、7/8(木) 19:00~20:00に開催予定です。
『実践Node.jsパフォーマンスアップ~Stream編~』と題して、主に中級者方向けの Stream を活用した Node.js のパフォーマンス改善方法をエンジニアの市澤がお話しします。
この発表を聞けば、処理高速化で節約した時間で美味しい料理が作れるようになるかも!
現在、connpassやTECH PLAYで参加受付中です。皆様のご参加をお待ちしております!
https://weseek.connpass.com/event/216686/
TECH PLAYはこちらから
一緒に働く仲間を募集しています
東京の高田馬場オフィス、大分にある別府サテライトオフィスにてエンジニアを募集しております。
中途採用だけではなく、インターンシップも積極的に受け入れています!
詳しい募集要項は、弊社HPの採用ページからご確認ください。
- Brigade | Event-driven scripting for Kubernetes.
- 99.9% は、旧スタンダードプラン以上、'21/5/13リリースの新法人プランではベーシックプラン以上での提供です
- Liveness Probe、Readiness ProbeおよびStartup Probeを使用する
- specifications/server-monitoring.rst at master · mongodb/specifications
- npm i elasticsearch
- https://github.com/hackmdio/codimd/blob/e00eaa82a98423b9eeb904b9c9fc8fc939f9f6e6/lib/models/index.js#L20-L24
- https://github.com/weseek/growi/blob/301f2283bae6f1adc195403ef0a2024b8c3bf78c/src/server/routes/apiv3/healthcheck.js#L80
- https://artifacthub.io/packages/helm/codimd/codimd?modal=template&template=deployment.yaml
- Configure Liveness, Readiness and Startup Probes | Kubernetes
- https://github.com/weseek/growi/releases/tag/v3.7.7
- https://github.com/weseek/growi/releases/tag/v4.2.3
- gcloud container operations list | Cloud SDK のドキュメント
- Regional clusters | Kubernetes Engine Documentation

